Dongfeng Gu
Twitter timeline architecture in 2012
- 2 minsThis post demonstrates the twitter timeline architecture in 2012 according to the video in here.
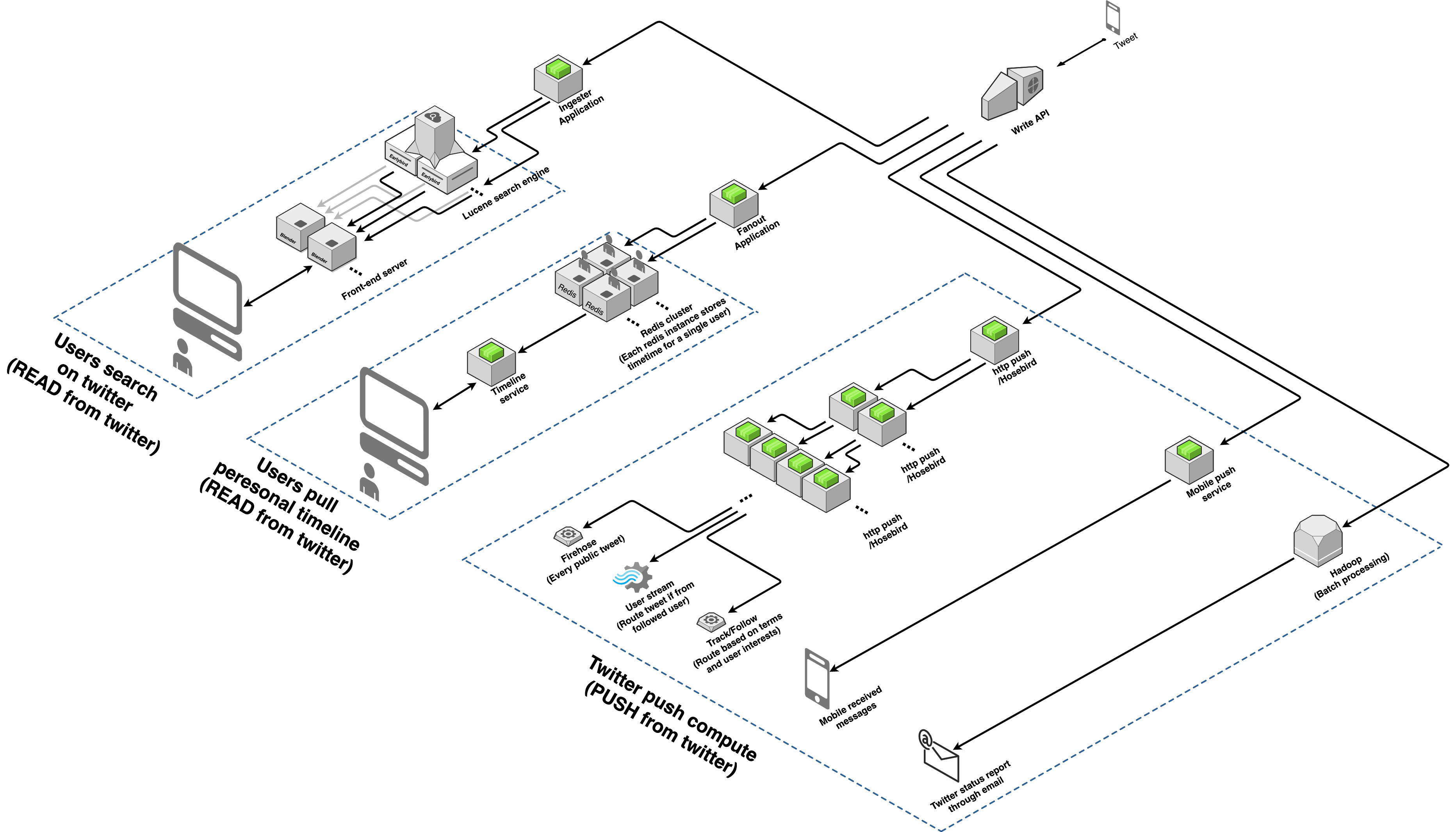
What will happen if a user posts a tweet
- Tweet goes through the load balancer and reaches the twitter write API
- Twitter write API will send the tweet to the following application/service asynchronously
- Ingester Application
- Parse/tokenize the tweet content, place the content inside one of the Earlybird instances for indexing according to the tokenization result.
- Fanout Application
- Find all followers of the user and insert the tweet to the Redis instance of those followers.
- Notice that each user had at least one Redis instance to store their timeline.
- Each fanout instance will take a portion of followers (ex: 4000) of the user and start inserting. This can parallel the inserting work and reduce latency (Within second).
- Redis data structure: Tweet ID (8 bytes), User ID (8 bytes), Bits (4 bytes)
- Hosebird / HTTP push
- event-based “router”: new tweets, social graph updates (follow & unfollow), user profile change, preference change, etc
- Every time an event comes in, Hosebird will cascade the event to another set of Hosebirds, which connect to more Hosebirds. There are four Hosebird cascading layers before it connects to a real client.
- Mobile push service
- Hadoop
- Run nightly batch analytic to generate a summarization email for users around the world, give the user recommendation on which topic they might be interested in.
- Ingester Application
What will happen if a user retrieves his/her timeline
Timeline service will take the user id and figure out which Redis instance has that user’s timeline. Then, it will pull out the timeline for that user, which contains a list of tweet ids and user ids. After that, timeline service will call tweet service, user service, and few other services to compose a fully render JSON. Finally, it returns this JSON to the frontend.
What will happen if a user search in twitter
Blender will generate the query according to search content. Then it will hit every Earlybird instances and check if that instance has anything that matches the query. Finally, Blender will merge the result returned by Earlybird and response.