Dongfeng Gu
从Tensorflow代码中理解LSTM网络
- 6 mins目录
参考文档与引子
缩略词
RNN (Recurrent neural network) 循环神经网络
LSTM (Long short-term memory) 长短期记忆人工神经网络
当我们在谷歌搜索LSTM这个关键字时,搜索结果的第一条就是一篇非常著名的博客 Understanding LSTM Networks 来介绍LSTM网络,这篇博客的作者是 Christopher Olah,在谷歌 Google Brain 工作。这篇博客的中文翻译版为 [译] 理解 LSTM 网络。
Tensorflow是一个由谷歌开发的基于Python语言的开源机器学习库。它具有跨平台(手机/个人电脑/服务器都可使用,CPU/GPU随意切换),高效率,高度自定义化,可以充分利用计算机性能等特点,在近几年中越来越受到机器学习研究者的喜欢,许多大公司也都在使用Tensorflow,诸如 ARM,snapchat,Uber,京东 等。
在本篇博客中,我将尝试通过解释Tensorflow中RNN/LSTM部分的源码来帮助大家深入理解LSTM网络的运作,同时也是为了来帮助我自己更好的理解LSTM网络。这是本人尝试写的第一篇博客,欢迎大家来加来指正文中的错误或者不合理之处,也欢迎提出各种各样的建议或意见。谢谢!
LSTM与RNN的关系
有一篇非常有名的博客The Unreasonable Effectiveness of Recurrent Neural Networks 详细介绍了什么是RNN并且作者开源一个基于LSTM的多层RNN神经网络项目(使用了Torch),强烈建议没有看过的人或者对于RNN概念不是非常清楚的人进来看看。这篇博客还有中文翻译版本:链接
LSTM从本质上来说并不是一个完整的神经网络模型,它其实是对RNN神经网络中的神经元/隐含单元(CELL/Hidden unit)的一种变形与改进。在这种改变当中,LSTM在神经元中加入了一个状态(State)的概念用来储存长期的记忆(具体LSTM结构将会在博客的后面有介绍)。在很多网上面介绍LSTM的教程或者博客当中,他们其实都只给了LSTM神经元的结构,这是属于RNN框架中的一部分。所以说如果想要理解LSTM我们首先需要理解什么是RNN。
RNN
本篇博客的主要目的是在于将Tensorflow中的代码与LSTM和RNN的理论公式对接起来。让大家可以更容易的使用Tensorflow来开发属于自己的神经网络,或者让大家可以对LSTM与RNN有一个更加直观的从代码方面的理解。所以说本博客假设读者已经对LSTM与RNN有一定的了解,我将会直接从图片开始来解读RNN和LSTM。对于那些对RNN和LSTM没有概念的人,我建议可以从参考文档中的那篇博客开始读起。
首先让我们从全局查看RNN神经网络是如何运作的
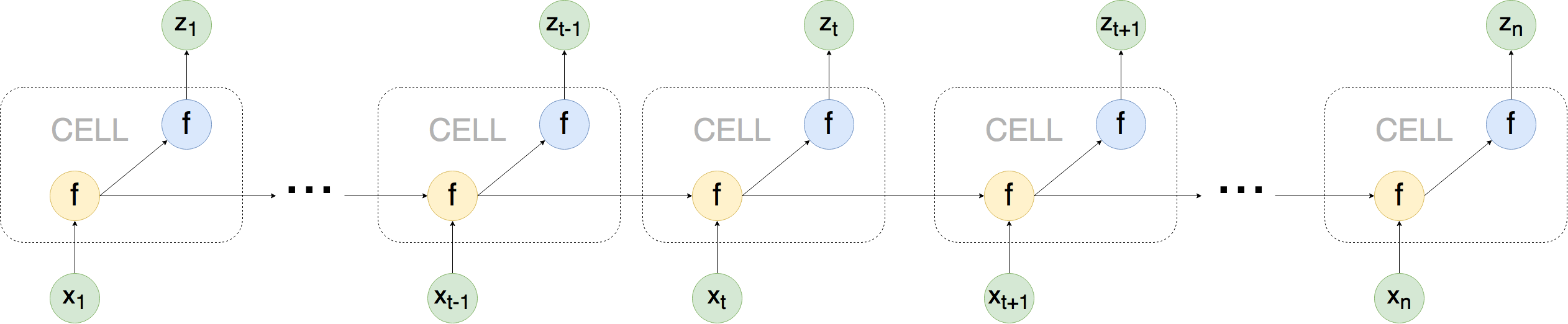
图中的 \(x\) 代表的是输入, \(z\) 代表的是输出,\(t\) 代表的是一段序列中任意的一个时间,\(n\) 代表的是当前序列的总长度。
下面让我们取上图中最中间的神经元为例来分析普通RNN神经元中的运作方式:
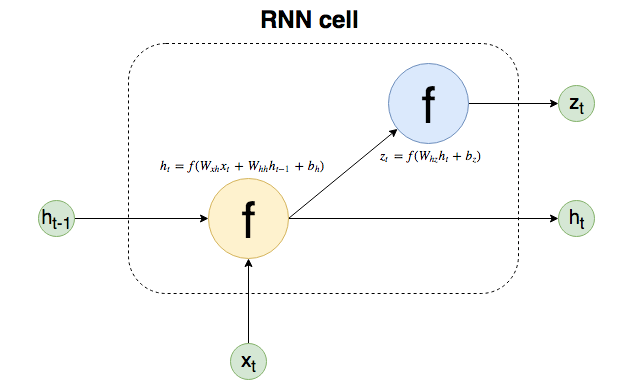
图中的 \(x_t\) 代表的是当前时间片段的输入, \(z_t\) 代表的是当前时间片段的输出,\(h_{t-1}\) 代表的是上一个时间片段的隐含状态输出,\(h_t\) 代表的是当前时间片段的隐含状态输出。中间的两个圆圈里的 \(f\) 代表的意思为一个非线性的点乘操作(element-wise non-linearity),可以为一个sigmoid操作或者是一个hyperbolic tangent的操作。
基础等式
\[h_t=f(W_{xh}x_t+W_{hh}h_{t-1}+b_h)\] \[z_t=f(W_{hz}h_t+b_z)\]对应的Tensorflow代码(Github)
def __call__(self, inputs, state, scope=None):
"""Most basic RNN: output = new_state = activation(W * input + U * state + B)."""
with vs.variable_scope(scope or type(self).__name__): # "BasicRNNCell"
output = self._activation(_linear([inputs, state], self._num_units, True))
return output, output
上述代码块对应的就是一个普通RNN神经元中的操作
"""Most basic RNN: output = new_state = activation(W * input + U * state + B)."""
下面是上述代码中的变量与基础等式中的变量的对应表
| 代码变量 | 基础等式变量 |
| new_state | \(h_t\) |
| W | \(W_{xh}\) |
| input | \(x_t\) |
| U | \(W_{hh}\) |
| state | \(h_{t-1}\) |
| B | \(b_h\) |
output = self._activation(_linear([inputs, state], self._num_units, True))
下面是上述代码对应的解释
| 代码 | 解释 |
| self._activation() | 激活函数,等同于基础等式中的 \(f\) 操作,在tensorflow的代码当中使用的是tanh的激活函数 |
| _linear() | 将传入的参数进行一个线性叠加的步骤 _linear([a,b], num_units, True) = \(Wa+Ub+B\) = \(W_{a_1}a_1+W_{a_2}a_2 + ... + W_{a_n}a_n + U_{b_1}b_1 + U_{b_2}b_2 + ... + U_{b_n}b_n\) 我们首先假设我们数据 批尺寸(batch size) = 10 输入数据大小(input size)= 300 隐含单元数(number of unit)= 200 那么 \(W\) 的大小为 [输入数据大小(input size)300, 单元数(number of unit)200]\(U\) 的大小为 [隐含单元数(number of unit)200,隐含单元数(number of unit)200]\(a\) 的大小为 [批尺寸大小(batch size)10, 输入数据大小(input size)300]\(b\) 的大小为 [批尺寸大小(batch size)10, 隐含单元数(number of unit)200]\(B\) 的大小为 [隐含单元数(number of unit)200](注意:在tensorflow代码当中,实际上tensorflow做的操作是 \(a*W+b*U+B\)。你会发现当完成操作 \(a*W+b*U\) 时,矩阵的大小是 [批尺寸大小(batch size)10, 隐含单元数(number of unit)200],但是 \(B\) 的大小却为[隐含单元数(number of unit)200],他们的大小无法匹配,但是tensorflow却可以把他们相加,这是因为tensorflow只是使用同样的 \(B\) 与矩阵中的隐含单元数相加。比如 [[1,2],[3,4]] + [1,1] = [[2,3],[4,5]]。) |
| inputs state | 这里的inputs就等同于上面解释的 \(a\), 这里的state就等同于上面解释的 \(b\) |
| True | 加入偏移(bias) \(B\) |
LSTM
下面让我们看一看LSTM,首先我们来看一下LSTM神经元的内部结构: 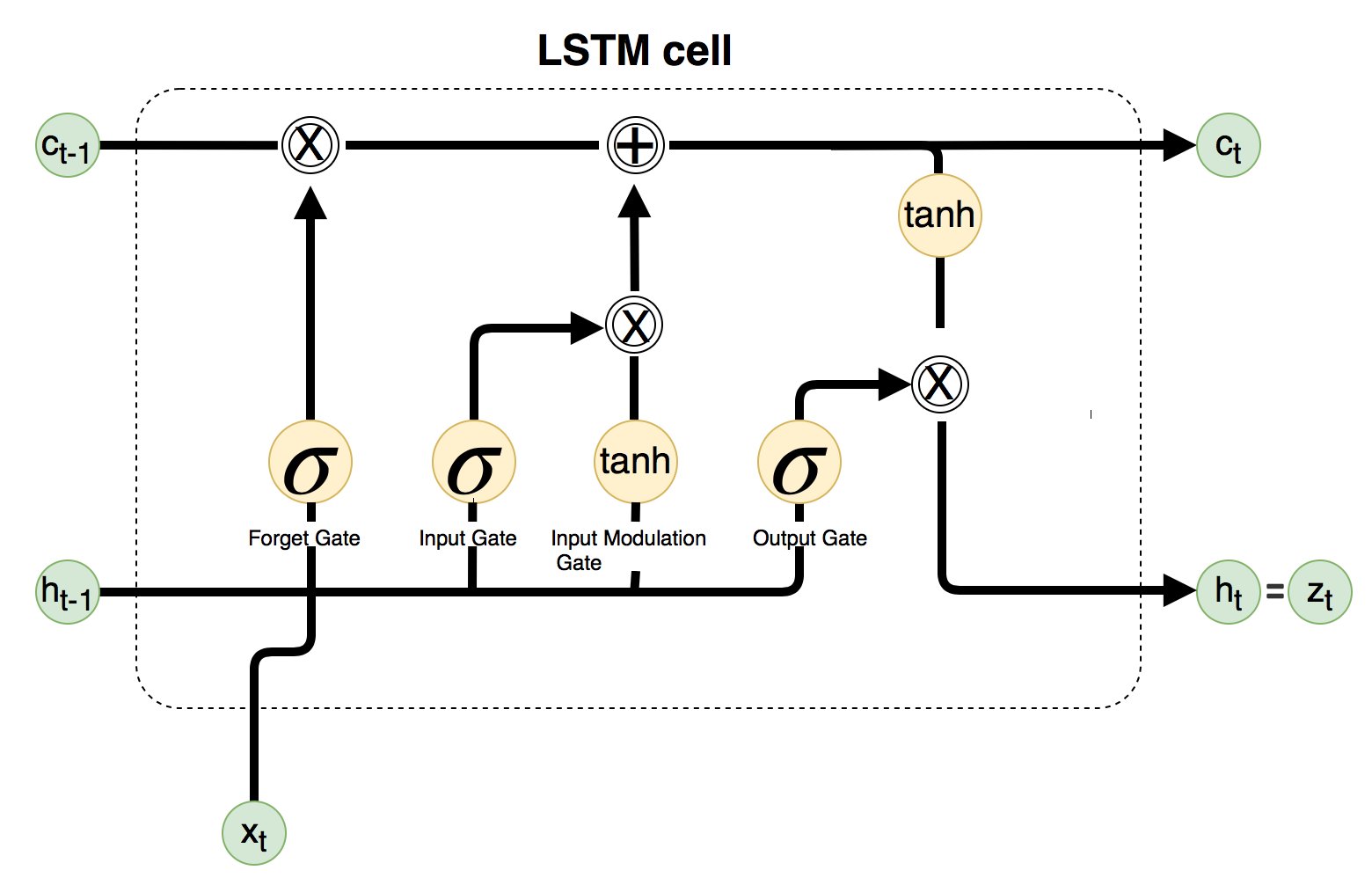
与RNN一样,图中的 \(x_t\) 代表的是当前时间片段的输入, \(z_t\) 代表的是当前时间片段的输出,\(h_{t-1}\) 代表的是上一个时间片段的隐含状态输出,\(h_t\) 代表的是当前时间片段的隐含状态输出。LSTM相较于RNN一个主要的区别在于LSTM添加了一个新的记忆单元 \(C\) ,图中的 \(C_{t-1}\)代表的是上一个时间片段的(旧)记忆单元,\(C_t\) 代表的则是当前时间片段的(新)记忆单元。图中的\(\bigotimes\)符号代表的意思是两个向量之间的点乘,图中的\(\bigoplus\)符号代表的意思则是两个向量之间的相加。图中圆圈里的 \(\sigma\) 代表的意思为为一个sigmoid操作,图中圆圈里的 \(tanh\) 则是是一个hyperbolic tangent的操作。
基础等式
\[Input Gate : i_t = \sigma(W_{xi}x_t+W_{hi}h_{t-1}+b_i)\] \[Forget Gate : f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+b_f)\] \[Output Gate : o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+b_o)\] \[Input Modulation Gate : g_t = tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c)\] \[c_t = f_t\otimes c_{t-1}+i_t\otimes g_t\] \[h_t = o_t\otimes tanh(c_t)\]对应的Tensorflow代码(Github)
def __call__(self, inputs, state, scope=None):
"""Long short-term memory cell (LSTM)."""
with vs.variable_scope(scope or type(self).__name__): # "BasicLSTMCell"
# Parameters of gates are concatenated into one multiply for efficiency.
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(1, 2, state)
concat = _linear([inputs, h], 4 * self._num_units, True)
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(1, 4, concat)
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat(1, [new_c, new_h])
return new_h, new_state
下面列表是上面代码中的变量的大小与解释
| 变量名 | 对应的基础等式变量 | 大小(shape) | 解释 |
| inputs | \(x_t\) | [批尺寸大小(batch size), 输入数据大小(input size)] | 输入的数据(\(x_t\)) |
| state | \((c_{t-1},h_)\) | ([批尺寸大小(batch size), 隐含单元数(number of unit)],[批尺寸大小(batch size), 隐含单元数(number of unit)]) | 这个一个tuple数据类型,储存了上一个时间段也就是旧的记忆单元(\(c_{t-1}\))和隐含状态(\(h_{t-1}\)) |
| c | \(c_{t-1}\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | 旧的记忆单元(\(c_{t-1}\)) |
| h | \(h_{t-1}\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | 旧的隐含状态(\(h_{t-1}\)) |
| i | \(W_{xi}x_t+W_{hi}h_{t-1}+b_i\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | Input Gate |
| j | \(W_{xc}x_t+W_{hc}h_{t-1}+b_c\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | Input Modulation Gate 也就是代码解释中的new_input |
| f | \(W_{xf}x_t+W_{hf}h_{t-1}+b_f\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | Forget Gate |
| o | \(W_{xo}x_t+W_{ho}h_{t-1}+b_o\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | Output Gate |
| new_c | \(c_t\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | 新的记忆单元(\(c_t\)) |
| new_h | \(h_t\) | [批尺寸大小(batch size), 隐含单元数(number of unit)] | 新的隐含状态(\(h_t\)) |
concat = _linear([inputs, h], 4 * self._num_units, True)
上述代码的_linear函数与之前RNN代码中的_linear函数一样。在函数里面,tensorflow会自动创建基础等式中相应的\(W_{xi}, W_{hi}, b_i, W_{xf}, W_{hf}, b_f, W_{xo}, W_{ho}, b_o, W_{xc}, W_{hc}, b_c\) 变量并初始化,在之后的过程当中,这些变量会随着输入的值的更新而不断的变化。
i, j, f, o = array_ops.split(1, 4, concat)
由于在上面的_linear函数中,tensorflow将input gate, input modulation gate, forget gate和output gate串联到了一起,并且他们的大小都是一致的为[批尺寸大小(batch size), 隐含单元数(number of unit)]。所以在这个步骤当中,tensorflow通过切割数组单独获取了input gate, input modulation gate, forget gate和output gate的值。
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
这一段代码对应的正是基础等式中的等式
\[f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+b_f)\] \[g_t = tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c)\] \[c_t = f_t\otimes c_{t-1}+i_t\otimes g_t\]new_h = self._activation(new_c) * sigmoid(o)
这一段代码对应的则是基础等式中的 \(h_t = o_t\otimes tanh(c_t)\) 最后tensorflow将新的隐含状态 \(h_t\) 返回,并将新的隐含状态和新的记忆单元串联起来之后返回。
结束语
至此我们应该对LSTM有了一定程度上的理解,欢迎读者们在下方评论区留言发表修改意见。谢谢!